
Deploying fine-tuned LLMs, hybrid RAG systems, and autonomous agents that speak your business language.
Book A Free Consultation With Our Experts
From chaos to clarity - Extracts key terms, sentiment, and actions → Auto- generates executive summaries

EYour institutional memory, on demand - Pulls precise answers from manuals/SOPs → 95% accurate responses

Speaks your language fluently - Understands 'SKU' = inventory ID, not just 'stock'

The universal translator - Connects APIs/databases → Eliminates silos
Where Other AI Stops, Ours Begins
Our AI doesn’t just execute tasks—it learns and evolves with your operations. Self-rewiring neural architecture adapts weekly to new patterns, while real-time process mining identifies bottlenecks before they impact performance. With self-correcting feedback loops delivering 99.4% error recovery, it’s like an invisible workforce that never sleeps.
"A global logistics firm reduced customs clearance time from 3 days to 47 minutes while cutting errors by 82%."Book A Free Consultation With Our Experts
Our AI specialists achieve operational fluency in your industry within 48 hours through advanced knowledge graph construction and BERT-based entity recognition, mapping your product hierarchies, customer pain points, and system integrations with 95% terminology accuracy from day three.
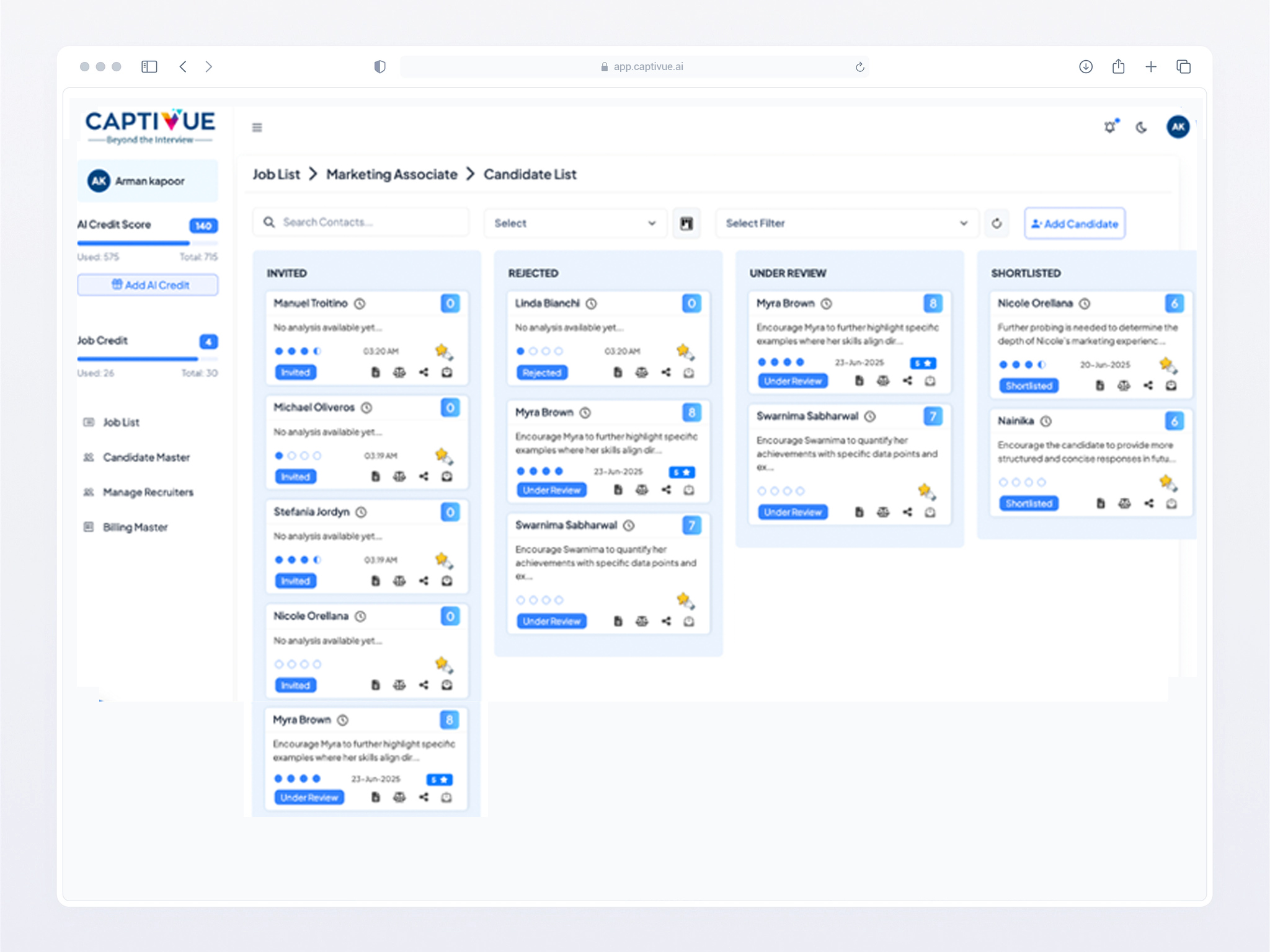
We employ process mining algorithms and path optimization to identify high-ROI automation targets, jointly reviewing compliance-critical decision points and integration touchpoints to build a precision automation blueprint that delivers measurable impact.
Custom RAG pipelines and LoRA-adapted Mistral-7B models deploy within 72 hours of project kickoff, with quantized GPTQ optimization ensuring sub-500ms inference latency for real-time enterprise operations.
Your assigned strike team - comprising an NLP architect for domain adaptation, MLOps engineer for Kubernetes deployment, and QA lead for F1-score optimization - implements GitOps-managed CI/CD pipelines to maintain 93%+ accuracy SLAs from launch.
Our fine-tuned LLMs don't just understand language - they speak your industry's vocabulary, reducing training time by 70% compared to generic AI solutions.
Unlike static systems, our models improve weekly through active learning feedback loops, automated concept drift detection and human-in-the-loop reinforcement
It is the core foundation of all our solutions and one of the driving force to be different. We contractually commit to a 93%+ accuracy on all automated decisions, < 500ms response times for critical workflows and 40% process automation within 30 days
Every solution includes a private LLM hosting in your VPC, SOC2 Type II compliant data pipelines and zero-downtime update cycles
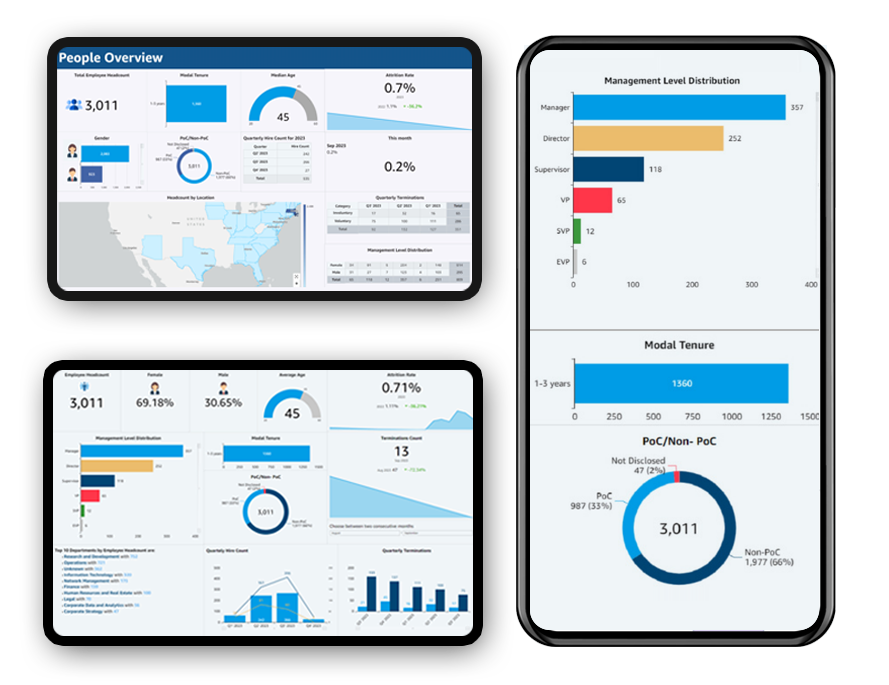
Most clients achieve positive ROI within 90 days when targeting high-volume repetitive tasks (e.g., document processing, tier-1 support). Our phased deployment starts with a "quick win" process—typically automating 20-40% of manual effort in the first 30 days.
We don’t use raw foundational models. Every solution combines:
1. Fine-tuned task-specific models (e.g., Deberta for contract review)
2. Your private data in RAG systems with NLI verification
3. Continuous feedback loops via human-in-the-loop training
All models deploy in your VPC/AWS account. We use:
Our monitoring stack includes:
Yes. Pre-built connectors for:
Through:
Auto-scaling inference pods (K8s + KEDA) with:
By 2025, 90% of enterprises will use AI-augmented processes, but only those with domain-specific tuning will achieve transformational results. - Gartner AI Research, 2024